|
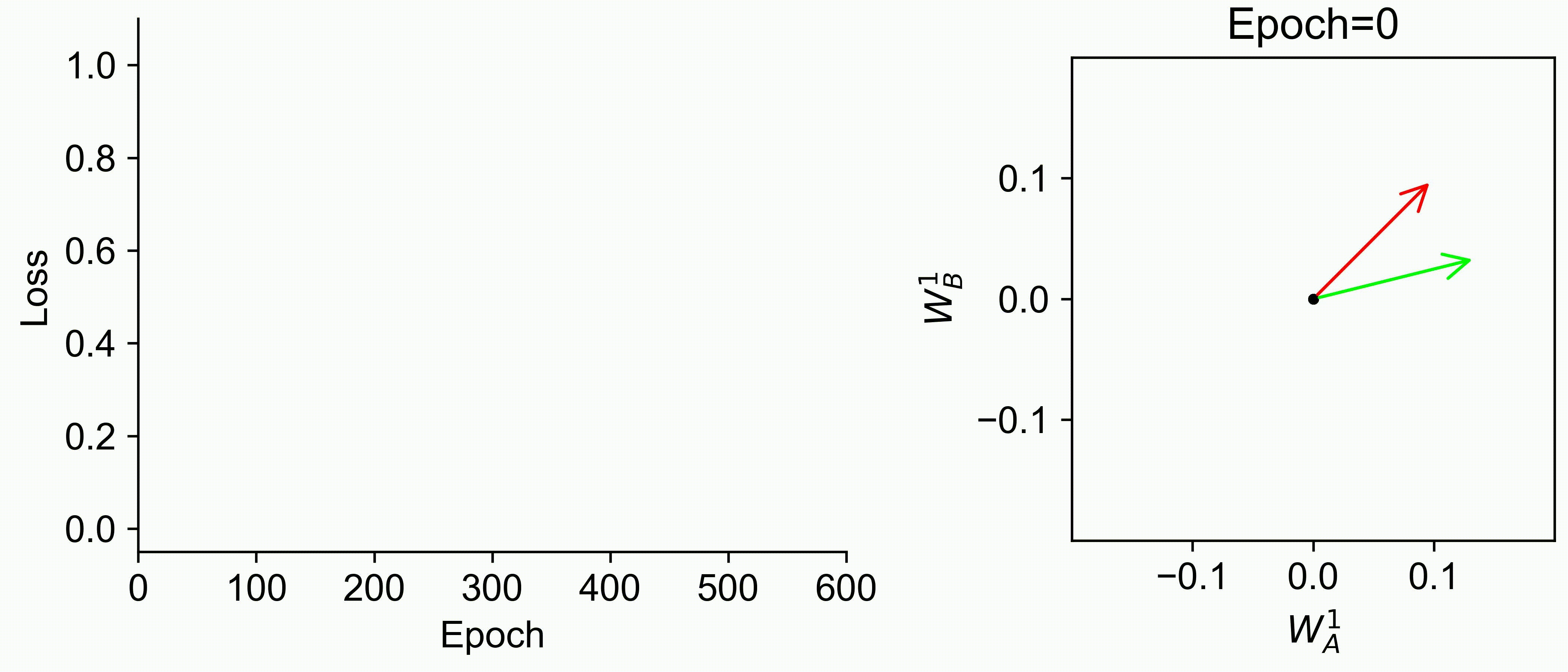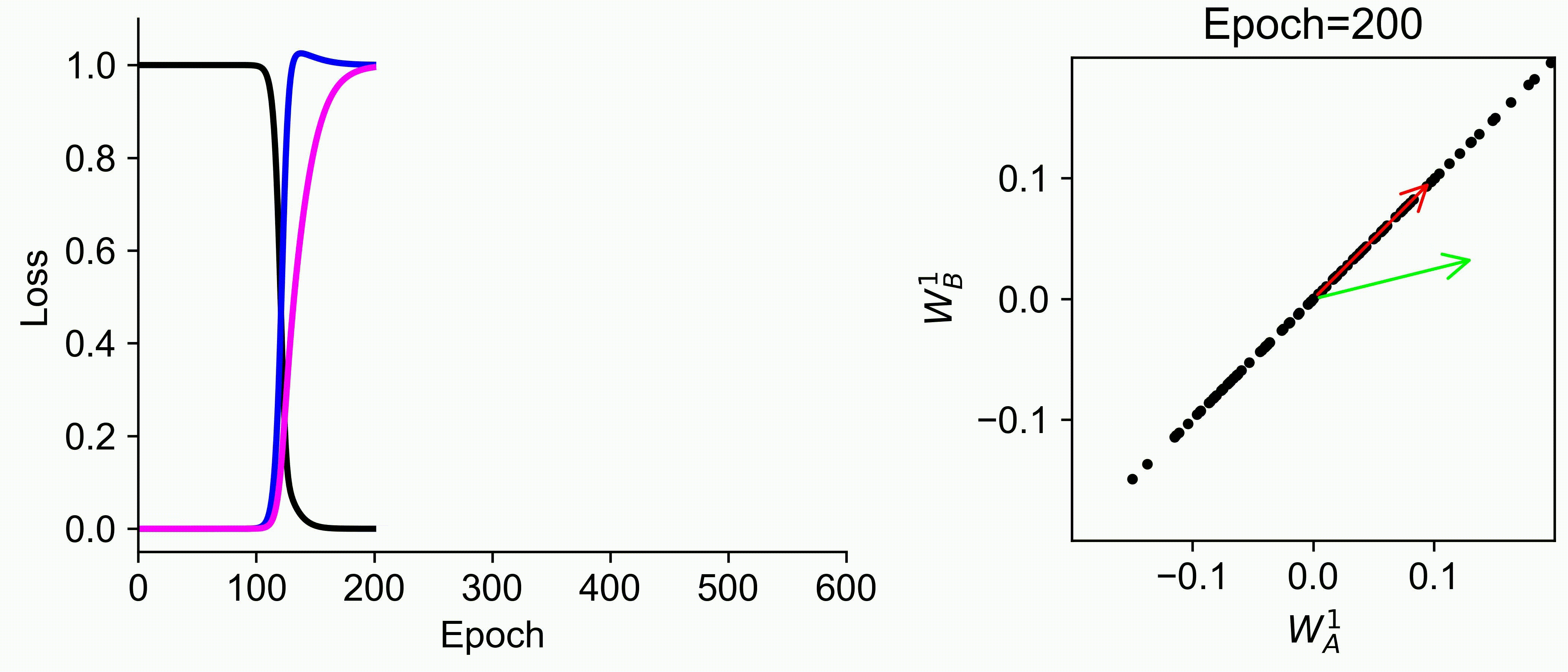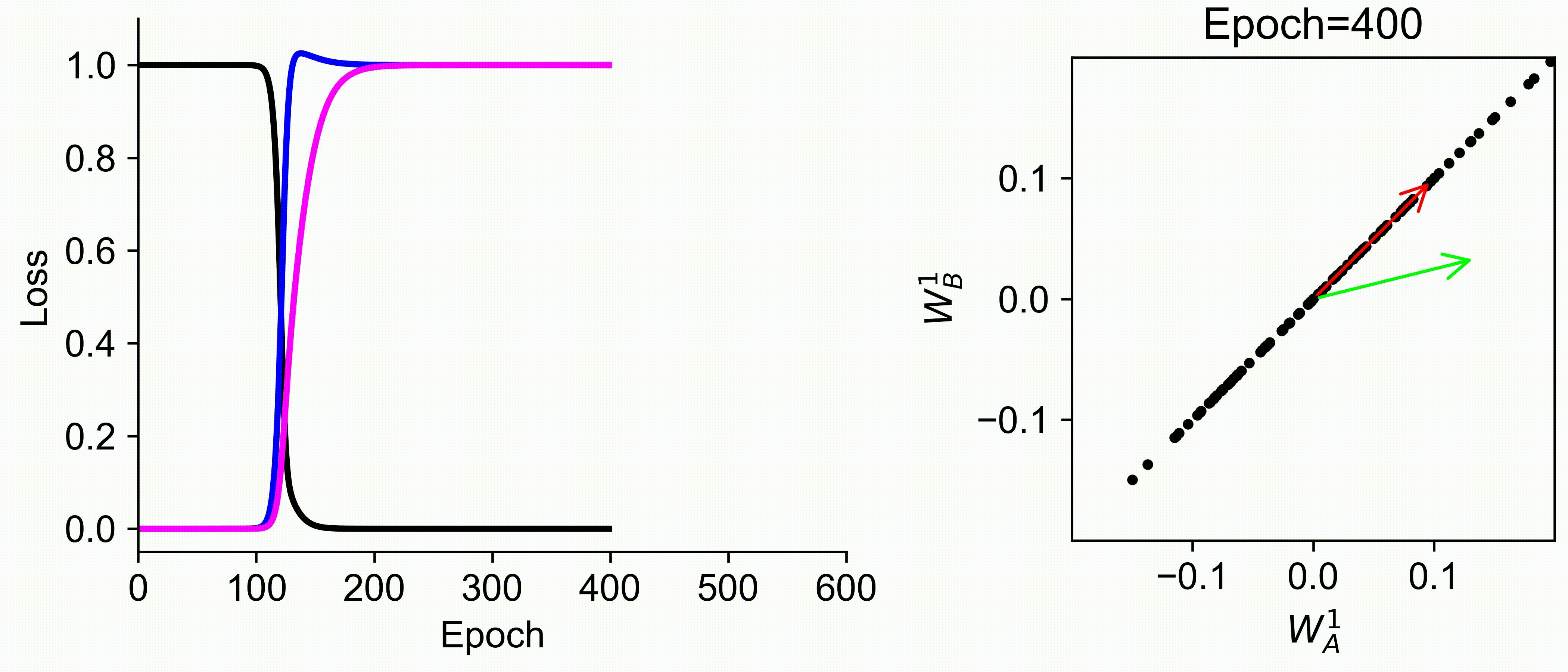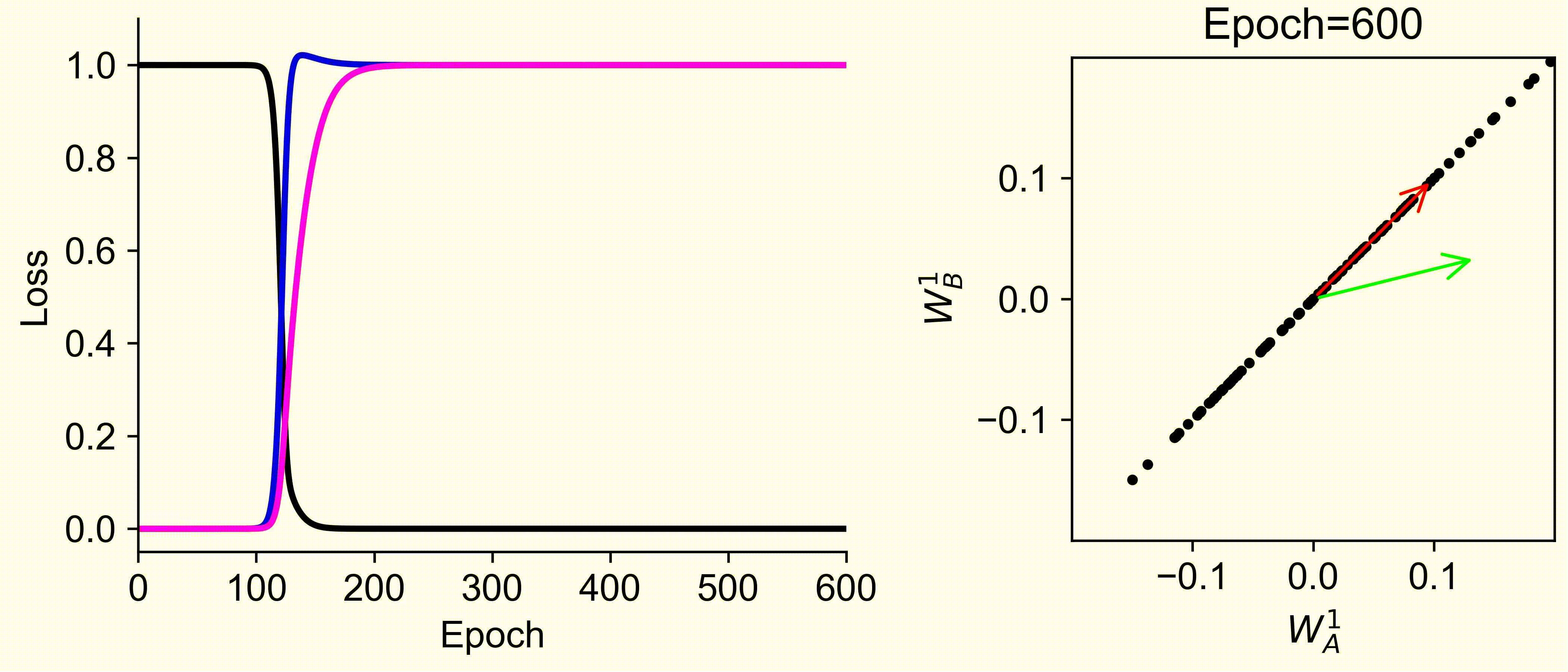
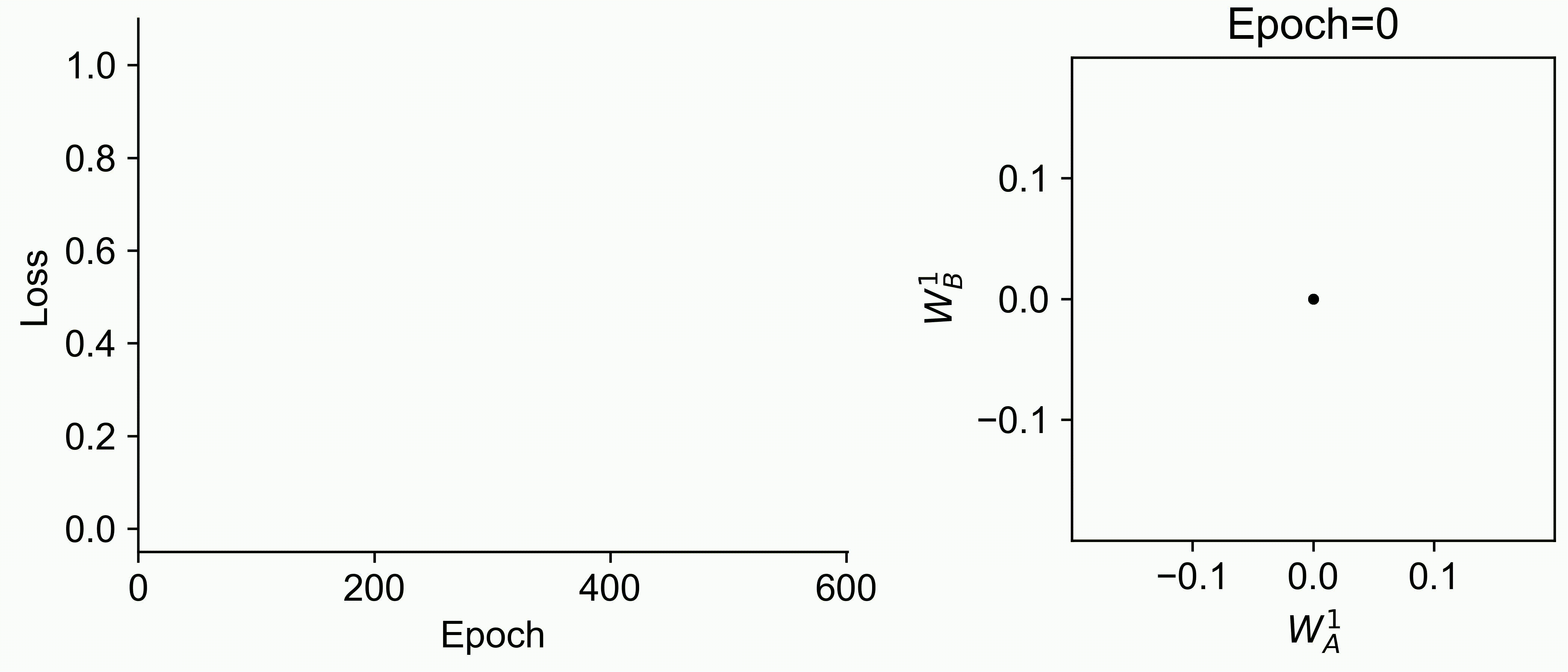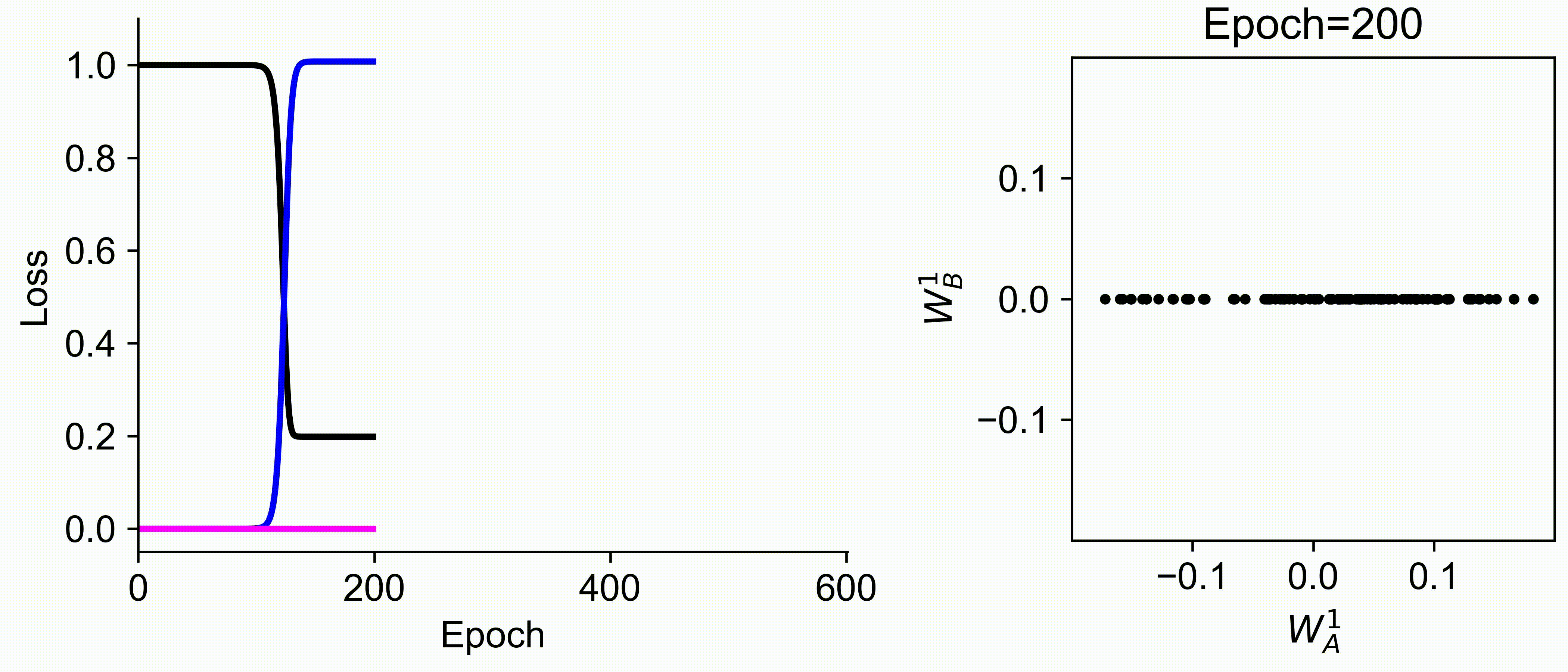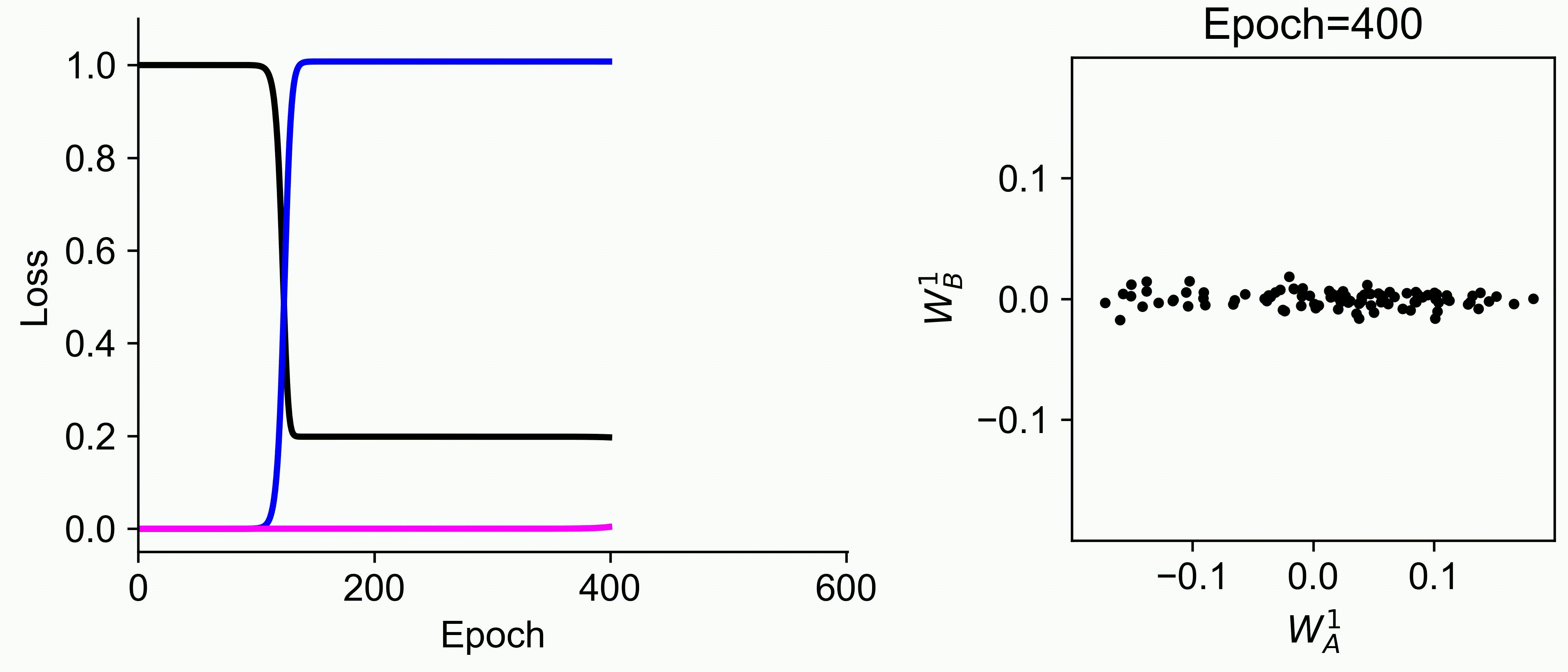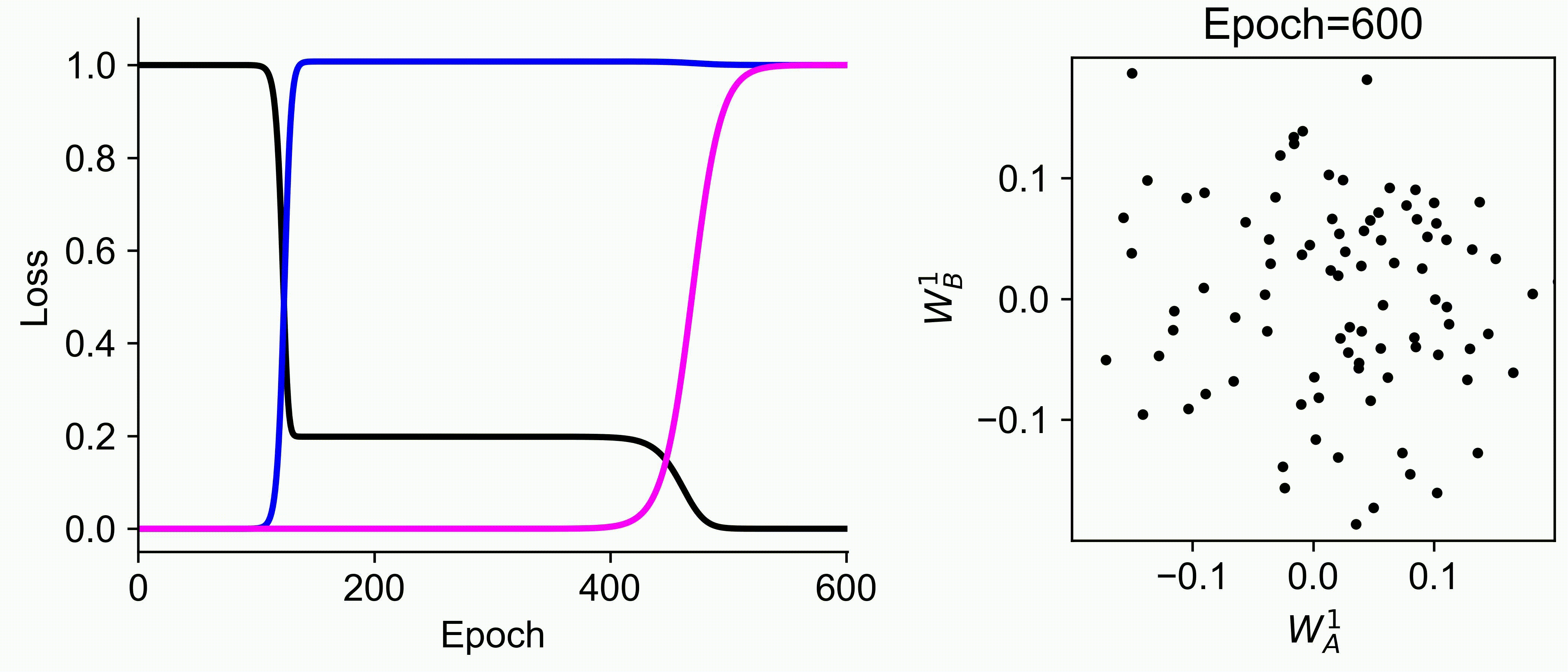
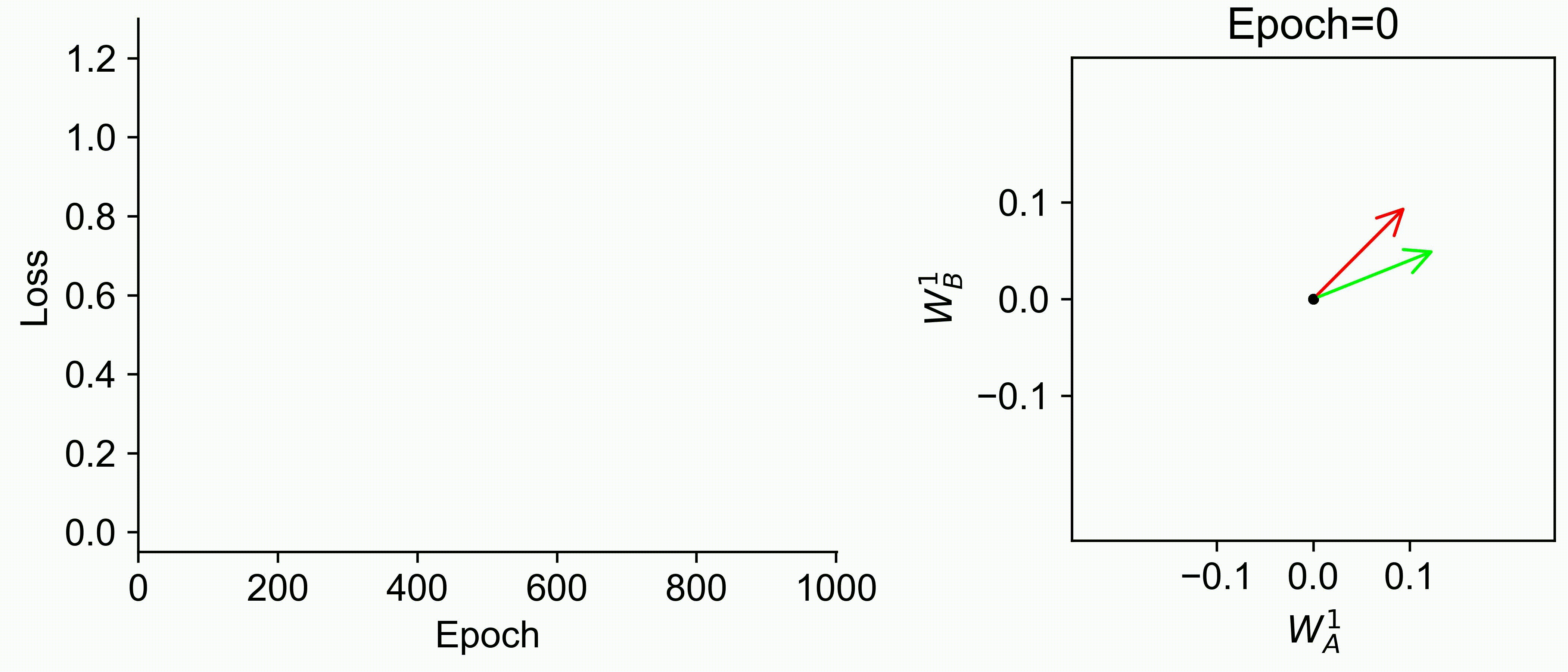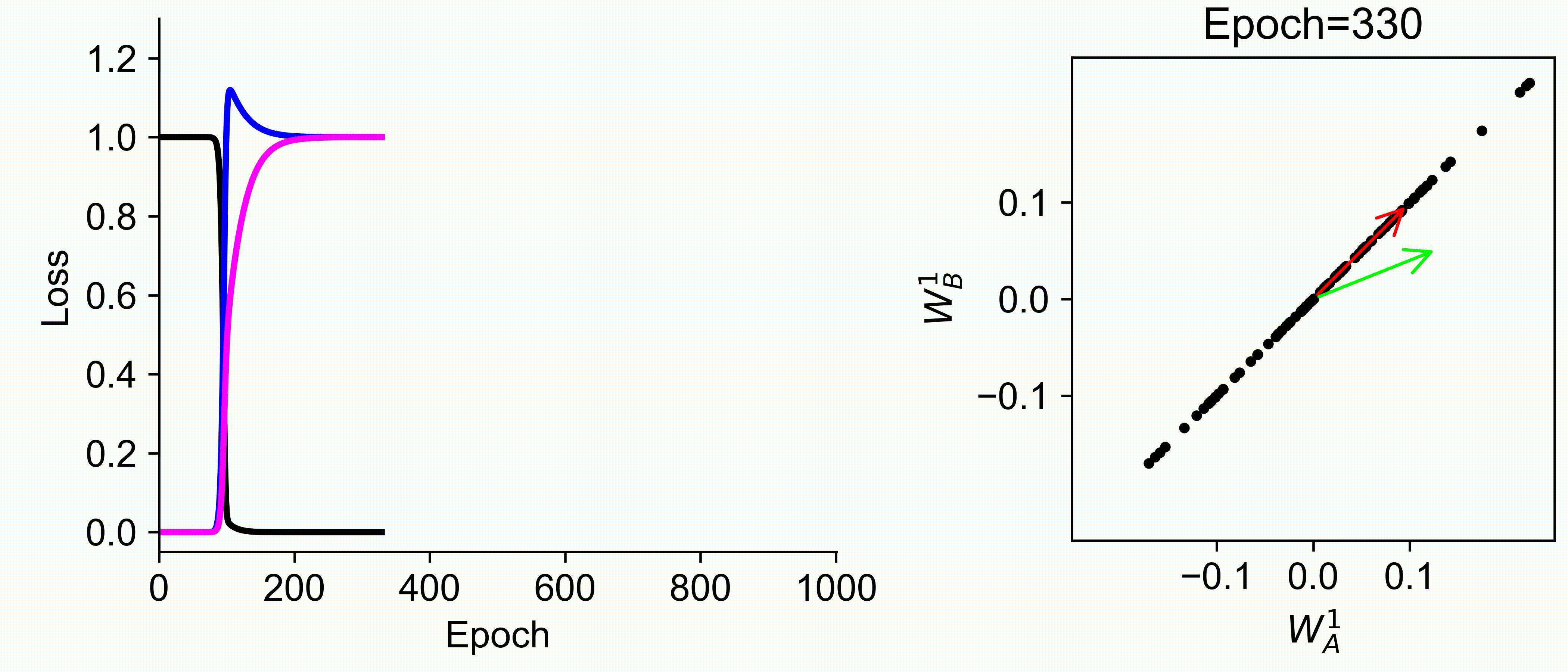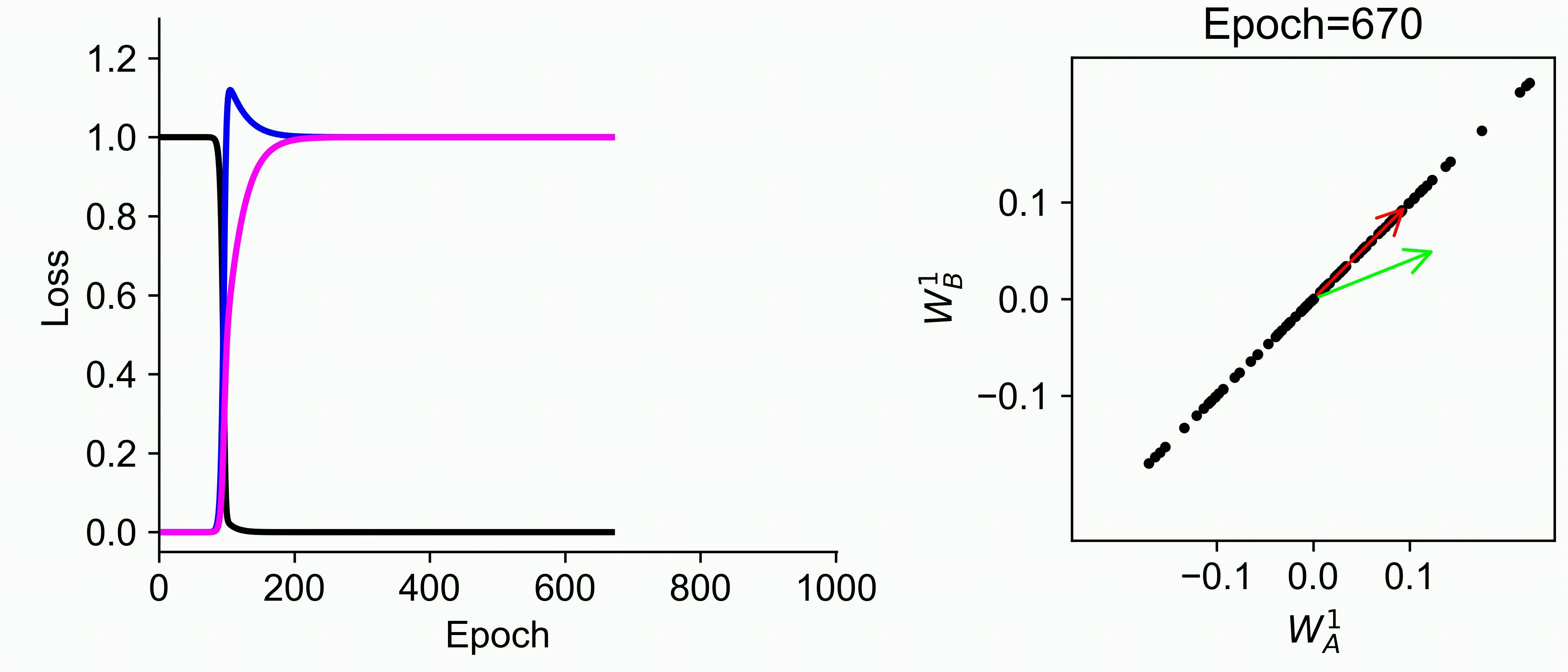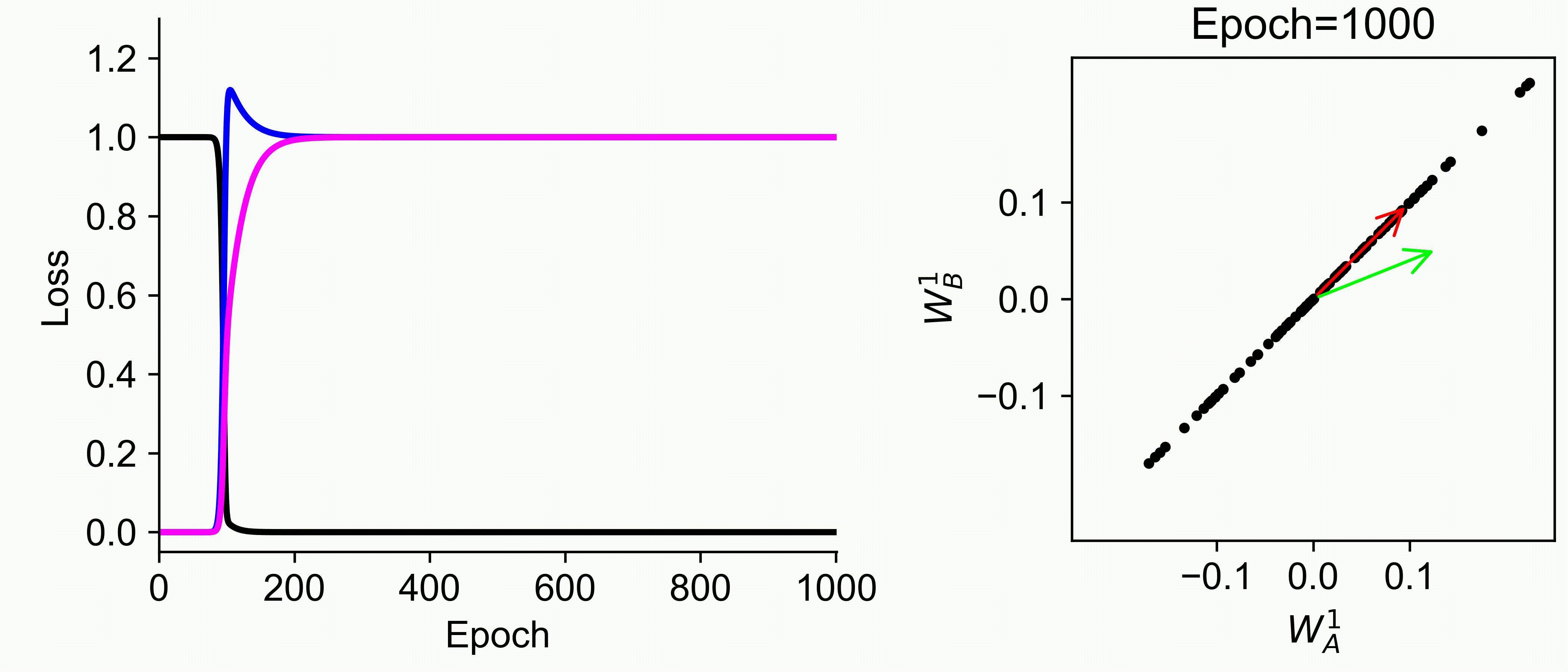
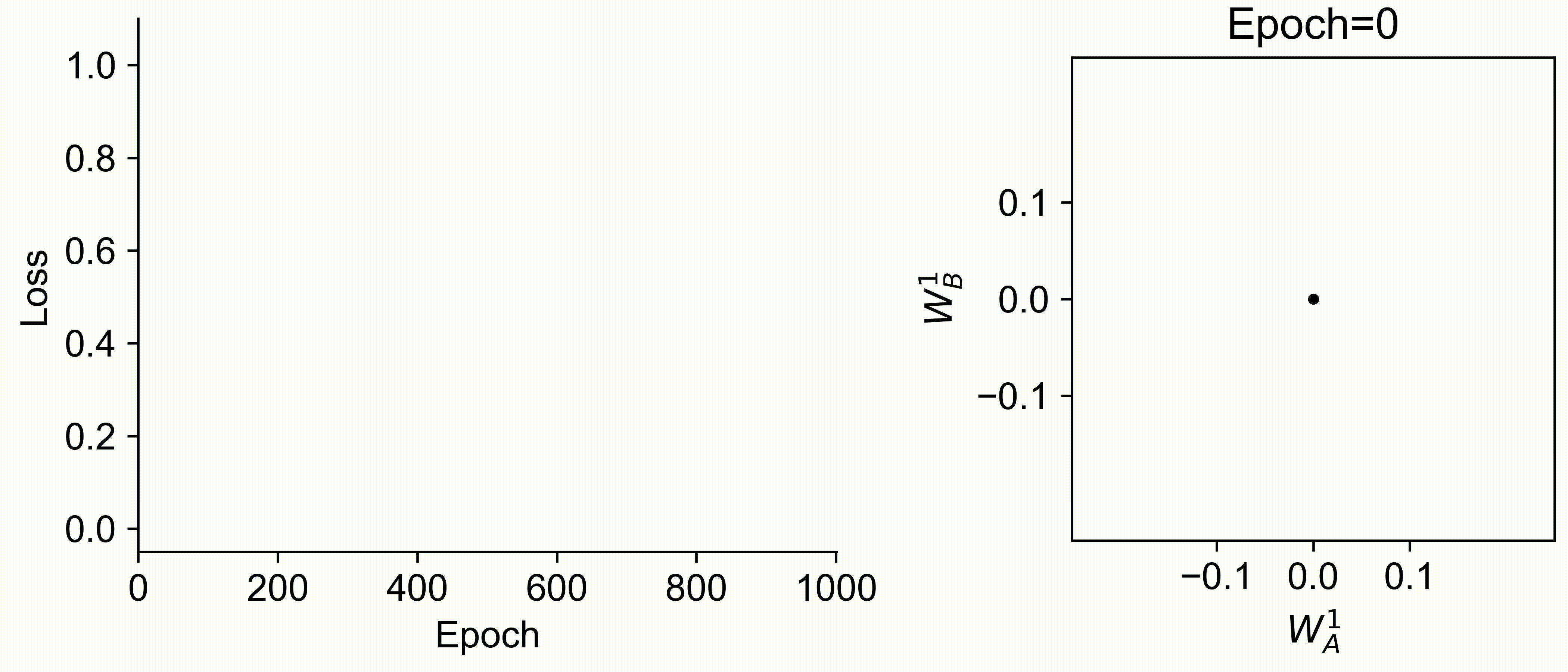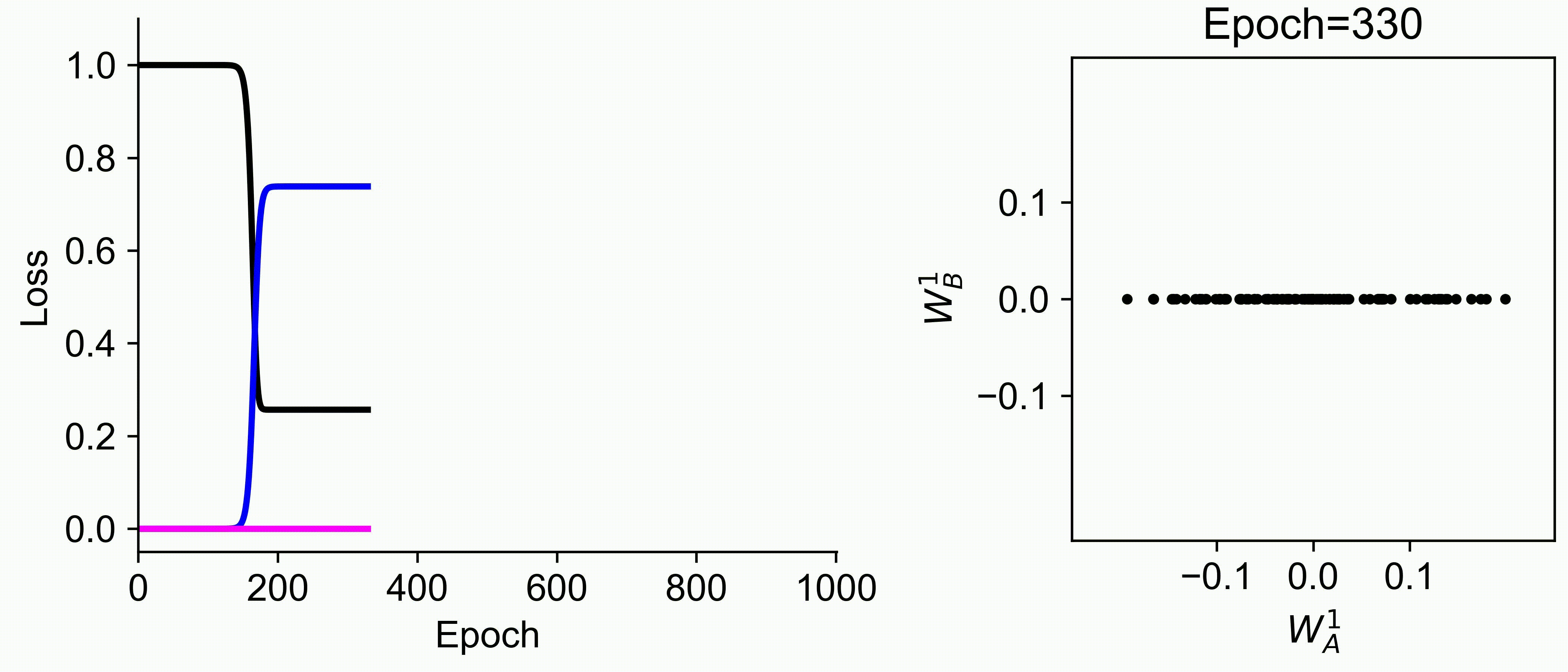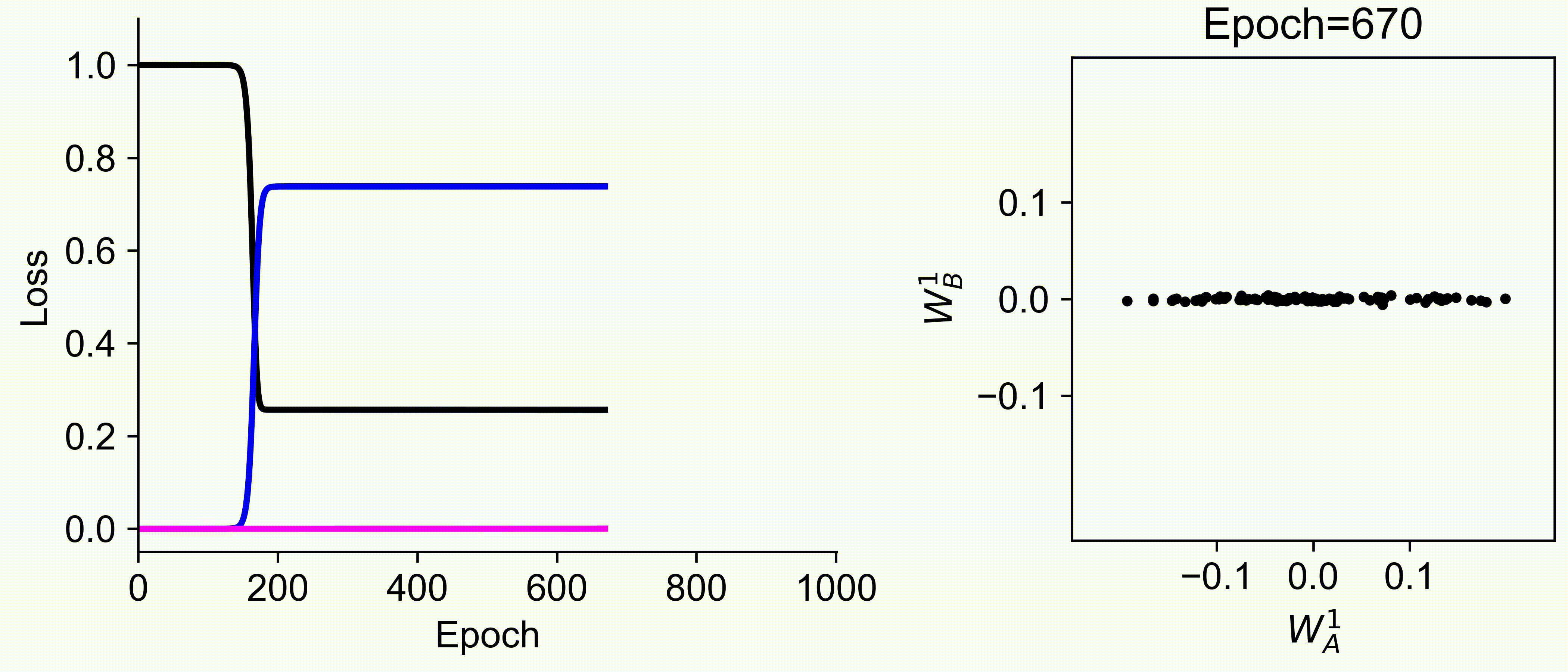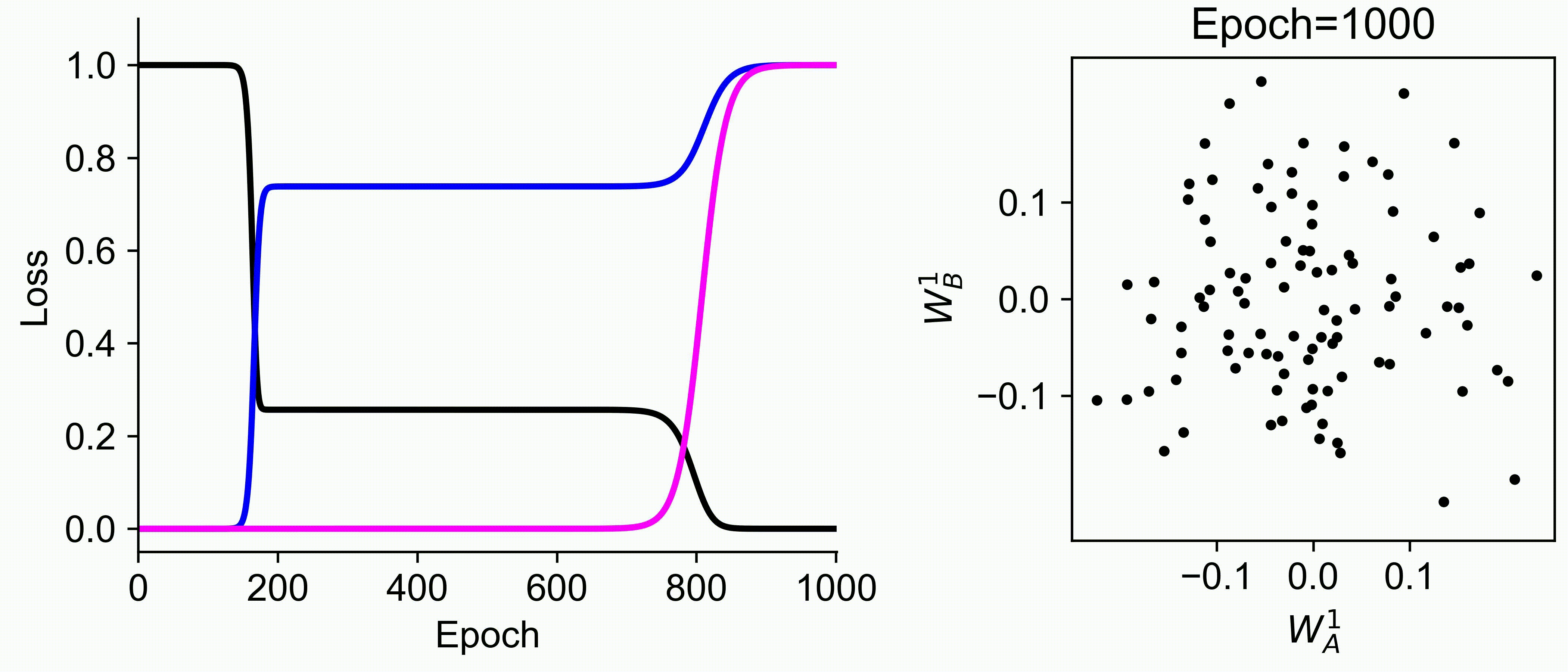
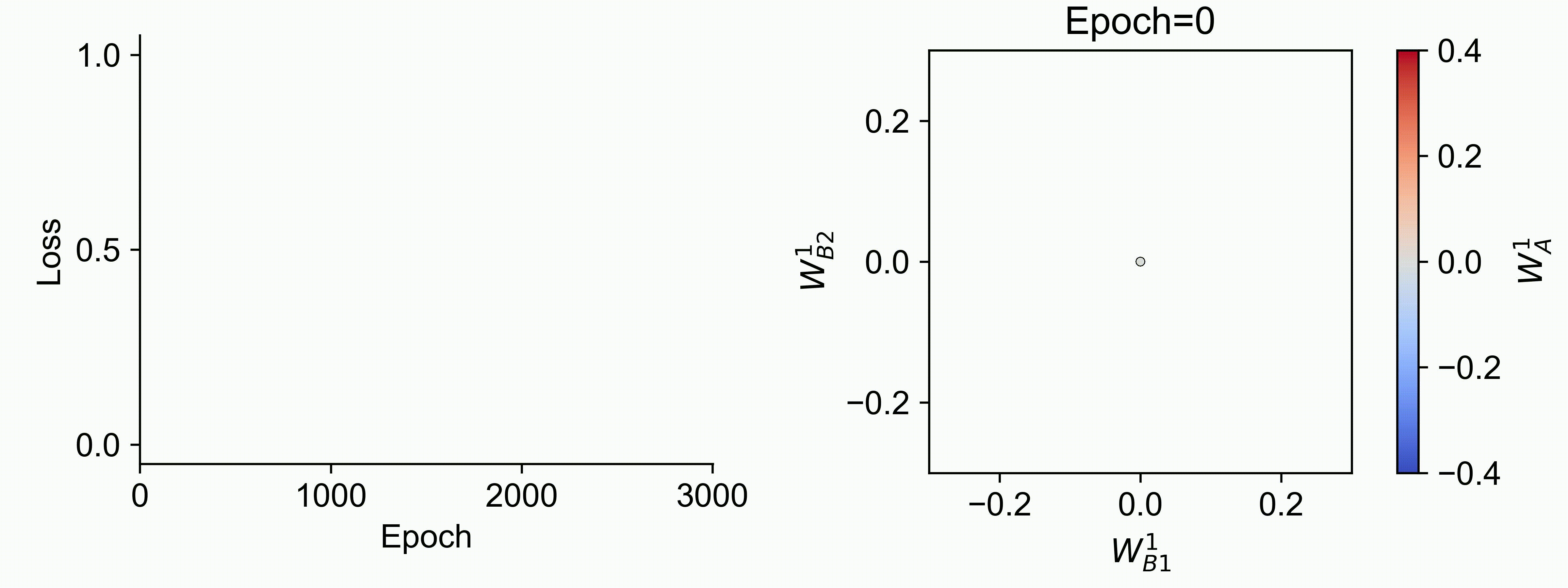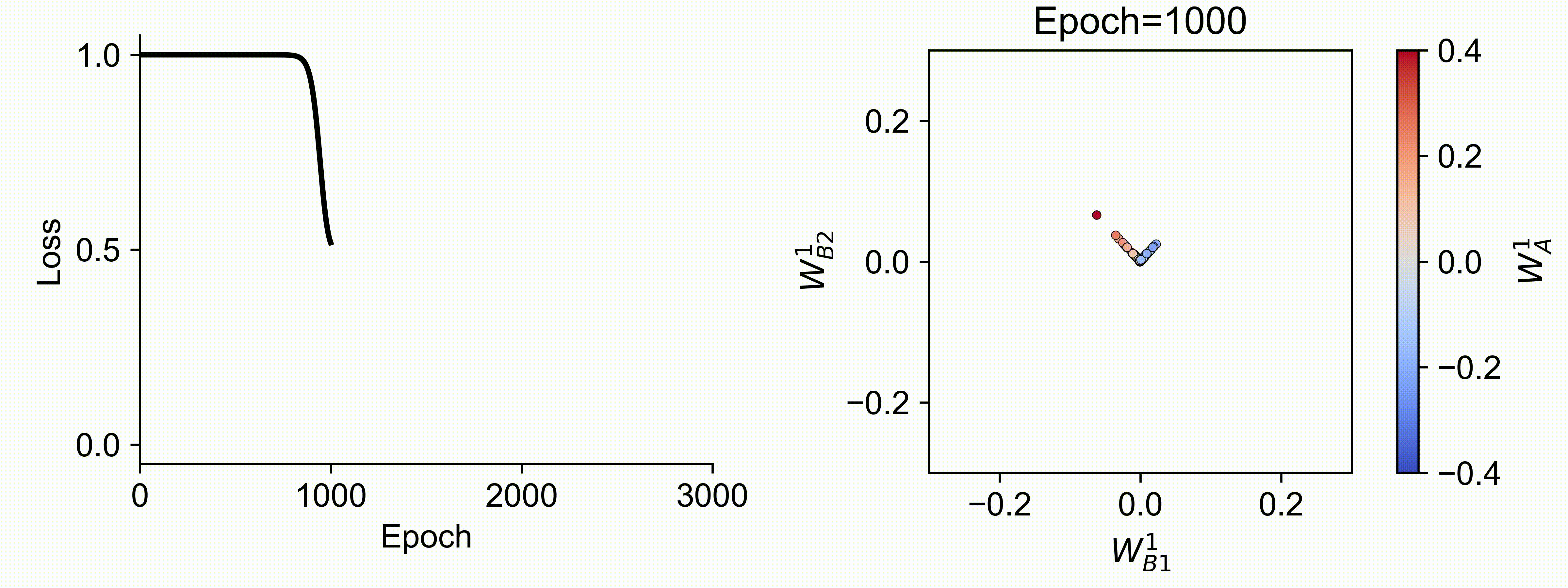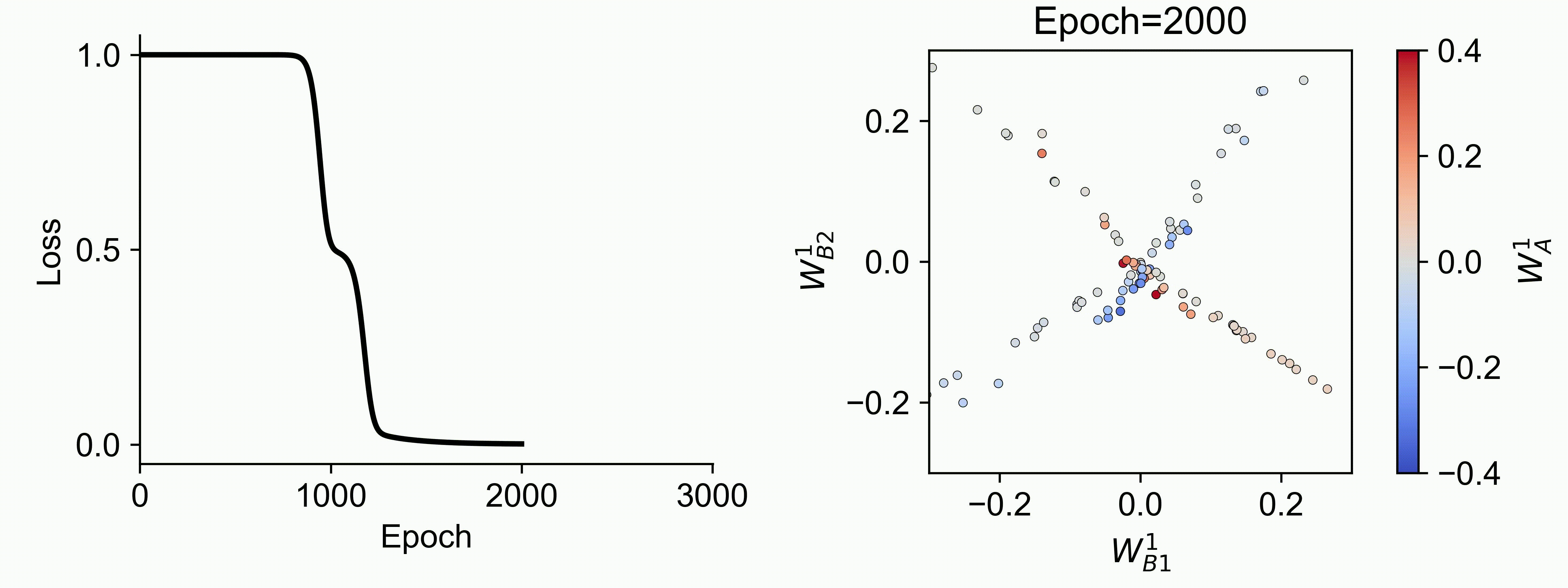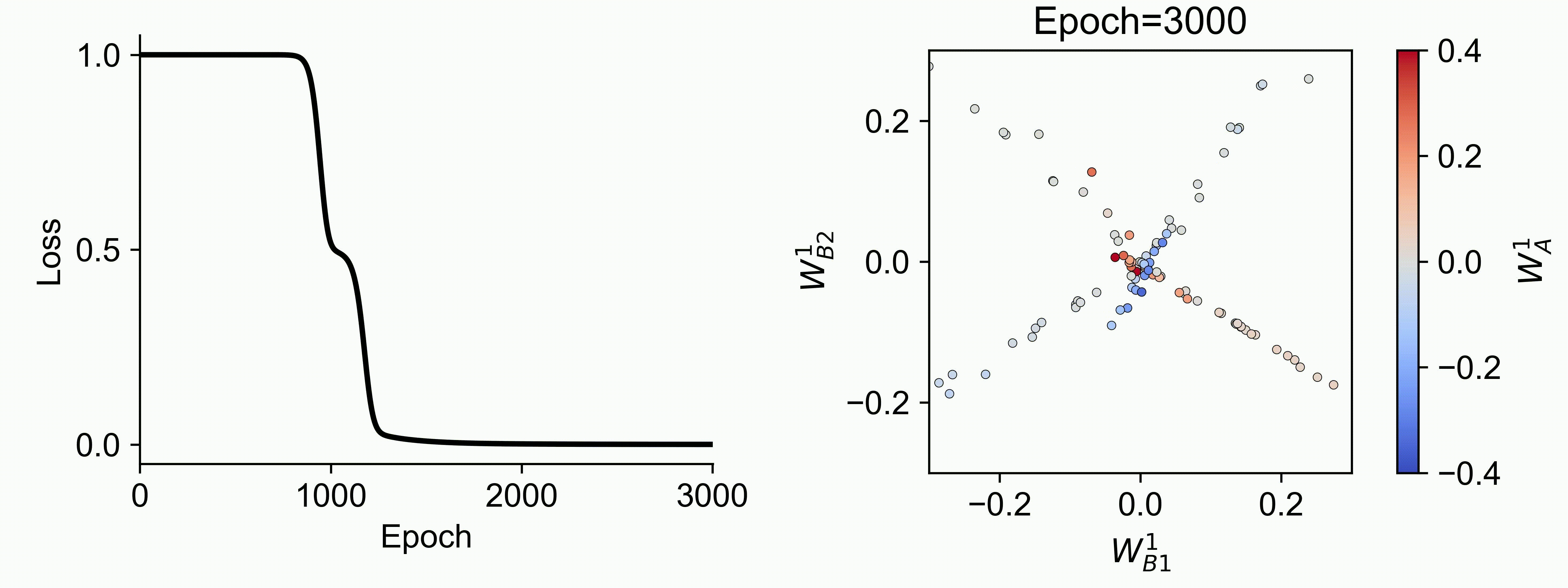
Using multiple input streams simultaneously to train multimodal neural networks is intuitively advantageous but practically challenging. A key challenge is unimodal bias, where a network overly relies on one modality and ignores others during joint training. We develop a theory of unimodal bias with multimodal deep linear networks to understand how architecture and data statistics influence this bias. This is the first work to calculate the duration of the unimodal phase in learning as a function of the depth at which modalities are fused within the network, dataset statistics, and initialization. We show that the deeper the layer at which fusion occurs, the longer the unimodal phase. A long unimodal phase can lead to a generalization deficit and permanent unimodal bias in the overparametrized regime. Our results, derived for multimodal linear networks, extend to nonlinear networks in certain settings. Taken together, this work illuminates pathologies of multimodal learning under joint training, showing that late and intermediate fusion architectures can give rise to long unimodal phases and permanent unimodal bias.
|